

|
|
|
|
|
|
|
|
|
|
|
|
|
 |
The World Wide Web and your privacyFor sure, you can no longer imagine day-to-day life without the World Wide Web. Those numerous services such as online banking, travel information, encyclopedias or the like mean a great convenience in solving your common tasks. Furthermore, you probably surf entertainment and shopping portals, stay in touch with friends over social networks or share your common interests with others in forums. To access the Web you are offered a dozen of stable, highly functional yet easy to use applications, the browsers. The most popular browsers are the Internet Explorer, Firefox, Opera, Safari and Chrome. Any communication on the Internet leaves all kinds of digital traces which can be automatically acquired, saved and analyzed. Some companies have thus specialized in creating individual user profiles from surfing related data. These databases are of high economic value since they allow an enterprise to comprehensively profile their costumers, that means you. This process is called data accumulation or data enhancement in data mining lingo. There are many reasons why one should avoid leaving digital traces when surfing: part of the data collected advects into scoring systems which are used to evaluate loan requests, to create individually priced offers or to decide on eligibility for C.O.D. service. Employers may be generated a character profile of their job applicants from traces on the Net prior to hiring them. Freedom of opinion is limited by governments or institutions where they trace individual surfers that use or edit certain web services or deny them any usage at all. Companies may recognize employees of other businesses or even those of their competition and subsequently annoy them with promotional calls or email spam. Browser related data exposes vulnerabilities in the surfing machine. An hacker may subsequently contact the computer directly and attack it. Further problematic is that these traces are collected, saved, sent and processed without your consent and most widely unnoticed. Decisions not being understandable by you may be based on this information. In the following three popular companies collecting and mining data get introdcued briefly. It is generally known that Google's business model is based on the analysis of collected data. But many users do have no conception regarding the comprehensiveness of personal profiles and the worth of these data. Economic figures: According to an estimation done by experts there are ca. 1.5 million servers working for Google in different data centers. Every three months that amount is growing by 100,000. The annual costs of this infrastructure are approximately 2 billion dollar. Google's overall revenue is about 30 billion dollar every year with an anually profit of 7 billion dollar. 96 percent of Google's revenue is generated by personalized advertisements. (as at 2009) The whole infrastructure may be used for free. It is not paid by money but by data. According to the Electronic Frontier Foundation (EFF) Google is logging the traffic which can be linked to a particular person unambigously examining various characteristics. This affects the deployment of the search engine, of Google services like YouTube or Google Earth and applies as well to flashing advertisements on other web sites and of course to tracking tools like Google Analytics. The basic data is combined to comprehensive profiles of individual users surfing the web. Due to its popularity Google is almost able to capture the whole searching and surfing behavior. In Germany 89 percent of search requests go directly to Google. Besides, 85 percent of german web sites are contaminated with elements (Google Analytics, flashing of advertisements et cetera) allowing Google to track users across multiple web pages. How exact and comprehensive Google's personal profiles are is hard to say. As a basis to estimate this one can use the data the company is providing to its advertisement partners. The following figure shows the aggregated statistics of a not further mentioned web site: 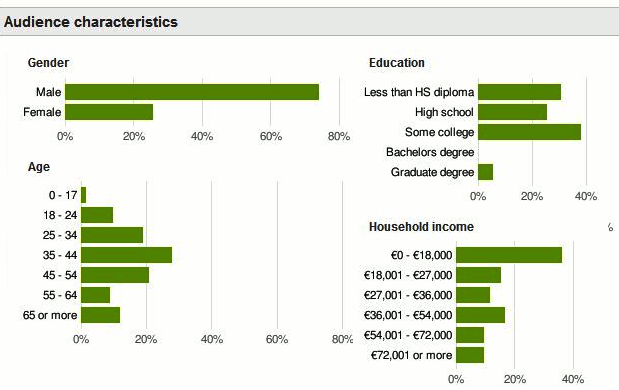
Besides age and gender Google is able to estimate the education level and income of almost all web surfers. Additionally, there are their interests, policital orientation and contact addresses (e-mail, instant messaging) that are not mentioned here but nevertheless collected by Google as well. As the Wall Street Journal writes in an analysis there are even ways to assess the likelihood of a payment by credit card. The researchers Bin Cheng und Paul Francis from Max Planck Institute for Software Systems show that it is possible to ferret out gay users by anaylizing clicks on advertisements. Their method can be adapted to any kind of questions and may for instance be used to deliver individual advertisments. The tracking and observation of users can be detected especially good in the case of retargeting. If one does not buy anything while visiting a web shop one is often overwhelmed with advertisements of similar products in the aftermath. Google is offering a special AdSense program with retargeting. RapLeafThe company RapLeaf is collecting data profiles via e-mail addresses. The data is not used for personalized advertisements. Rather, it is just sold. As a potential buyer one is passing a list of e-mail addresses to RapLeaf and gets the profiles back (according to the comprehensiveness intented) after paying the bill. The following is a short abridgement out of the price list (as at 2011):
The data is gathered by correlating e-mail usage with surfing behavior or obtained via the time and time again happening data leaks at online merchants' platforms. One of the main investors is Peter Thiel, who founded PayPal and is co-determining the development of Facebook in the background in a significant way. It has to be asssumed that RapLeaf uses data collections of these internet companies as well. Furthermore, data stemming from Twitter and other data bases offering commercial access is included into the processing. Economic figures: The "social net" Facebook is supposed to have 600 million users worldwide. The stock exchange value of the company is estimated to 50 billion dollar and the profit was 353 million dollar in 2010. The earnings amount to 4-5 dollar for every user in one year. (as at 2011) Facebook is for free and the user's data is the basis for the commercial success as well. Data that is entered intentionally and in a controlled way is only playing a minor role here. Far more important is the information extracted out of the users' behavior. This data and the derived information is not controlled by users. But they have agreed to a commercial use of them when they registered themselves.
Facebook is going to be a "net within the net" with orwellian visions. Economic figures: Twitter has an estimated amount of 200 million users. Every single user causes costs of about 1 dollar a year. (as at 2010) Contrary to Google and Facebook Twitter did not manage it to use the data itself profitably. The earnings out of the advertisements fell far short of expectations. Twitter's business model is selling access to its database. Twitter is providing 40 parameters (content, location, date, account, used software, language, retweets...) for every Tweet. Paying 60,000 dollar a year one can access 5 percent of the Tweets, paying 300,000 dollar a year one can access the whole database. Twitters database is a rich source of information that may not be found somewhere else for market research purposes, advertisements or secrect services.
|
|
||||||||||||||||
|
|
|
|||||||||||||||||
