|
|
|
|
|
|
|
|
|
|
|
|
|
 |
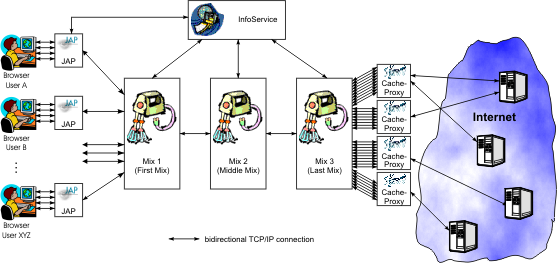
Architecture of the Anonymization ServiceThe structure of the JAP anonymization service is shown schematically in the following diagram. It consists of the following components:
How It WorksWhen you start the JAP client program, JAP first connects to the InfoService to check if the program version is still current. If the version of the program is no longer compatible with the software of the mix, the user is automatically offered a program update, since otherwise the JAP service could no longer be used.In the next step, JAP registers with the first mix station of the chosen mix cascade. A permanent network connection between JAP and the first mix station remains until logoff. On installation of JAP, the user already configured the web browser so that each packet of data sent goes through JAP instead of directly to the internet. JAP encrypts the data and sends it to the first mix station. The first mix station then mixes the data with that of other users and sends it to the second mix station which passes it on to the third mix station which decrypts and sends the data through a cache proxy to the internet. Each mix carries out cryptographic operations on the message so that the JAP-encrypted data is only readable when it's gone through the proper mixes in the proper order. That way it's insured, that an eavesdropper either only receives unreadable (encrypted) data or can no longer determine the sender. In order for it to work correctly, only one mix in the cascade need be trusted not to inform the eavesdropper as to the method of message mixing. Here is a description of the exact method of encryption. Weaknesses of JAPOur goal is to create an anonymization service which is secure against an attacker of almost any strength. There should be only two restrictions:
Possible AttacksJAP is not yet secure against such a strong attacker. Two theoretical attack possibilities against our service will now be described:If an attacker keeps all network connections under surveillance, each user would have to send and receive exactly as much data as any other user. Otherwise the attacker, who observes both the connection to the user and the connection to the internet after the final mix, could correlate a user based on the amount of data sent. If one user sends more data than all the other users, that's most likely the one communicating with another user who is receiving large amounts of data at the end of the cascade. Currently, we can't defend against such an attack for various reasons. Users have different connection speeds and varying amounts of activity at any given time. If one wanted to achieve an equivalent behavior pattern among all users who have the same connection speed, yet maintain a similar quality of service, the mixes would require many times the current bandwidth. In addition, any disturbance experienced by a single user would have an effect on all other users, since they would have to wait until the one user with the connection problems sent as much data as all the rest. A second theoretically possible attack is as follows: Currently a single attacker could simulate multiple users by simply starting several JAP client programs. That way, he could at least fool the remaining users into believing in a higher amount anonymity than what is really available. If the attacker would furthermore block all real users except for one, the anonymity of that single remaining user would be completely eliminated. To prevent this kind of attack, it would be necessary to authenticate every user at login, for example with a digital signature. With a pay-based service, such an attack could at least be made very expensive for the attacker. There are currently still other attacks possible, since the planned basic functions are not yet completely implemented. On the other hand, an attacker would have to be relatively strong in order to succeed in any attack known to us. You are already protected against an eavesdropper who can only eavesdrop on one point of the network or who controls only one of the mixes. Reasearch on JAPThe number of data packets per user on the Dresden-Dresden cascade are ocassionally, and for strictly limited time periods, counted for reasearch purposes. However, this tracking is not linked to individuals. The data is statistically processed and subsequently deleted. |
|
||||||||||
|
|
|
|||||||||||